
この記事ではtensorflowの”basic classification”というチュートリアルをやります。
スニーカーやシャツなどの衣服の画像を分類分けするための、ニューラルネットワークモデルが学べます。tensorflowをラップした高レベルのAPIのkerasも使います。
実行環境
anaconda (python3.6), Jupyter Notebook 5.7.4, tensorFlow1.12.0
モジュールのインポート
必要なモジュールをインポートした後、tensorflowのバージョンを表示します。
import tensorflow as tf from tensorflow import keras import numpy as np import matplotlib.pyplot as plt print(tf.__version__)
【結果】
1.12.0
参考までにJupyter Notebook での結果を一部載せます。
Fashion MNISTというデータセットをインポート
10個のカテゴリに分類された7万枚のグレースケール画像のFashion MNIST datasetを使用します。このそれぞれの衣類は低解像度(28x28ピクセル)で表示されています。
ニューラルネットワークの訓練データとして6万枚、テストデータとして1万枚を使います。
TensorFlowからFashion MNISTに直接アクセスできます。
fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
【結果】ログが表示されます。
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 4us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 103s 4us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 5us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 15s 3us/step
4つのNumPy配列が返されます。
train_images配列とtrain_labels配列のsetは訓練データ、test_images配列とtest_labels配列のsetはテストデータです。
28×28の2次元配列で、ピクセル値は0~255です。labelsは0~9のint型の配列です。0~9は以下の衣服の分類に対応しています。
| Label | Class |
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
クラス名はデータセットに含まれないため定義します。後ほどグラフ化するときに使用します。
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
データを調べる
分類を始める前にデータを調べる方法を紹介しています。
以下はtrain_imagesに6万枚の画像があり、各画像は28×28ピクセルである事を表しています。
train_images.shape
【結果】
(60000、28、28)
同様にラベルのサイズも調べてみると、60,000ラベルあることがわかります。
len(train_labels)
【結果】
60000
各ラベルは0~9までのint型であることがわかります。
train_labels
【結果】
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
省略しますが、test_images, test_labelsに関しても同様です。
データの前処理をする
データは前処理をする必要があります。トレーニングセットの最初の画像を調べるとピクセル値が0~255あることがわかります。
plt.figure() plt.imshow(train_images[0]) plt.colorbar() plt.grid(False)
【結果】
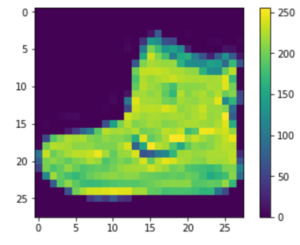
ニューラルネットワークモデルに与える前に、これらの値を0~1に変換します。どの様なタイプのデータでも0~1に変換することで同じ様に扱えて便利です。正規化と言われます。
大抵の場合、データがアルゴリズムの期待する型ではなかったり、大きさでない場合があるため正規化が必要です。
訓練データとテストデータを同じ方法で前処理することが重要です。次のコードは整数のデータセットを255.0で割って、float型のデータセットに変換しています。
トレーニングセットの最初の25枚をラベルをつけて表示してみましょう。データが正しい形である事を確認します。
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
【結果】

モデルを構築する
ニューラルネットワークを構築するためには、モデルのレイヤを設定した後にモデルをコンパイルする必要があります。
レイヤーを設定する
ニューラルネットワークの基本的な構成要素はレイヤーです。レイヤーは、そこに送られたデータから表現を抽出します。
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
最初のレイヤーであるkeras.layers.Flatten()は28×28の2次元配列を1次元配列に変換します。データを再フォーマットしただけであり、学習させるネットワークには関係ありません。
ネットワークは一連の2つのレイヤー keras.lavers.Dense で構成されます。ほとんどのレイヤーは訓練中に学習されるパラメータがあります。この2つのレイヤーは密接に、結合されたニューラルレイヤーです。
最初のDenseレイヤーは、128のノード(ニューロン)を持ち、2つ目のDenseレイヤーは10のノードから成るsoftmaxレイヤーです。softmaxレイヤーは合計が1になる確率スコアの配列を10個返します。各要素は、衣類の10分類の中の1つに属する確率です。
コンパイルする
モデルのコンパイル時に、損失関数、最適化、メトリクスを設定します。
- 損失関数 訓練中のモデルの精度を表します。この関数でモデルを正しい方向に操作する事を最小限に抑えることが理想です。
- 最適化 結果のデータとその損失関数に基づいてモデルを更新する方法です。
- メトリクス 訓練とテストの実行状況をモニターするために使われます。次の例ではaccuracy(正しく分類された割合)を使用します。
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])








コメントを残す