
この記事ではtensorflowの”text classification“というチュートリアルをやります。
このチュートリアルでは映画のレビューの文章を用いてポジティブかネガティブに分類する方法が学べます。
実行環境
anaconda (python3.6), Jupyter Notebook 5.7.4, tensorFlow1.12.0
モジュールのインポート
tensorflowとnumpyとtensorflowをラップした高レベルのAPIのkerasを使います。
import tensorflow as tf from tensorflow import keras import numpy as np
データセットのダウンロード
データセットは5万件の映画レビューを含むIMDBデータセットを使います。訓練データ2.5万件、テストデータ2.5万件に分けられます。
バランスを取るためポジティヴレビューとネガテイブレビューは同数存在します。
IMDBはTensorFlowに同梱されています。レビュー(単語の並び)が整数の並びになる様に変換されるよう前処理されています。各整数は辞書内の特定の単語を表します。
扱う文章は英語です。i → 1, use → 12, TensorFlow → 333,の様に単語に番号が振られているとしたら, “I use TensorFlow” という文章が [1, 12, 333]という整数の並びに変換されるイメージです。
次のコードはIMDBをダウンロードして変数にセットしています。num_words=10000とすることで、訓練データの中で最も出現する単語の上位10000単語を保持するように指定しています。
imdb = keras.datasets.imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
【結果】
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 21s 1us/step
データを調べる
データの数とラベルの数を調べます。
print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels)))
【結果】
Training entries: 25000, labels: 25000
最初のレビューを表示します。何かの単語に対応する整数のリストになっていることが確認できます。
print(train_data[0])
【結果】
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
最初と2つ目のレビューの長さを調べると2つの長さが違うことがわかります。ニューラルネットワークでは入力のサイズを同じにする必要があるため、後でこれを解決します。
len(train_data[0]), len(train_data[1])
【結果】
(218, 189)
整数を単語に戻す
整数を単語に戻す方法も知っておくと便利です。
#単語が整数にマッピングされた辞書を取得
word_index = imdb.get_word_index()
# 最初の要素を予約(単語を登録)
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # 不明な単語
word_index["<UNUSED>"] = 3
# 整数を単語にマッピングする辞書を作成
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
【結果】ダウンロードログが表示されます。
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 2s 1us/step
最初のレビューを文章で表示してみます。
decode_review(train_data[0])
【結果】
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
データを準備
整数の配列はニューラルネットワークに入力する前にテンソルに変換する必要があります。今回は整数の配列が全て同じ長さになるように変換します。サイズはmax_length × num_reviewsになります。これを最初の層として使います。
pad_sequense関数を使用して長さを標準化します。その後最初と二番目のレビューの長さを確認すると、同じ長さになっていることが分かります。
train_data = keras.preprocessing.sequence.pad_sequences(
train_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
len(train_data[0]), len(train_data[1])
【結果】
(256、256)
最初のレビューを表示すると後半が0で埋められていることが確認できます。
print(train_data[0])
【結果】
[ 1 14 22 16 43 530 973 1622 1385 65 458 4468 66 3941
4 173 36 256 5 25 100 43 838 112 50 670 2 9
35 480 284 5 150 4 172 112 167 2 336 385 39 4
172 4536 1111 17 546 38 13 447 4 192 50 16 6 147
2025 19 14 22 4 1920 4613 469 4 22 71 87 12 16
43 530 38 76 15 13 1247 4 22 17 515 17 12 16
626 18 2 5 62 386 12 8 316 8 106 5 4 2223
5244 16 480 66 3785 33 4 130 12 16 38 619 5 25
124 51 36 135 48 25 1415 33 6 22 12 215 28 77
52 5 14 407 16 82 2 8 4 107 117 5952 15 256
4 2 7 3766 5 723 36 71 43 530 476 26 400 317
46 7 4 2 1029 13 104 88 4 381 15 297 98 32
2071 56 26 141 6 194 7486 18 4 226 22 21 134 476
26 480 5 144 30 5535 18 51 36 28 224 92 25 104
4 226 65 16 38 1334 88 12 16 283 5 16 4472 113
103 32 15 16 5345 19 178 32 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]
モデルを構築する
ニューラルネットワークはレイヤーを重ねることによって作成されます。これには、以下の主なアーキテクチャを決めなければいけません。
- いくつモデルでレイヤーを使うか?
- それぞれのレイヤーにいくつ”隠れユニット”使用するか?
以下のコードでモデルを作成します。
# 入力サイズは映画レビューで使われた単語の数です(10,000単語) vocab_size = 10000 model = keras.Sequential() model.add(keras.layers.Embedding(vocab_size, 16)) model.add(keras.layers.GlobalAveragePooling1D()) model.add(keras.layers.Dense(16, activation=tf.nn.relu)) model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid)) model.summary()
【結果】
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding (Embedding) (None, None, 16) 160000 _________________________________________________________________ global_average_pooling1d (Gl (None, 16) 0 _________________________________________________________________ dense (Dense) (None, 16) 272 _________________________________________________________________ dense_1 (Dense) (None, 1) 17 ================================================================= Total params: 160,289 Trainable params: 160,289 Non-trainable params: 0 _________________________________________________________________
これらのレイヤーを順番に積み重ねて分類器を構築します。
第1レイヤー Embeddingレイヤー
このレイヤーは整数に変換された単語を得て、単語埋め込みベクトルを調べます。これらのベクトルが訓練用モデルとして学習されます。このベクトルは次元を1つ追加した配列を出力します。結果は、(batch, sequence, embedding)です。
第2レイヤー GlobalAveragePooling1Dレイヤー
このレイヤーは、それぞれの次元の平均を取ることで、各例の固定長ベクトルを返します。可能な限り簡単な方法で可変長の入力を処理できます。
第3レイヤ Denseレイヤー
出力された固定長ベクトルは16の”隠れユニット”を持つ完全に接続されたレイヤー(Denseレイヤー)を通してパイプ処理されます。
最後のレイヤー Denseレイヤー
このレイヤーは単一の出力ノードと密接に接続されています。シグモイド関数を使用することで、確率または信頼水準を表す0~1の値になります。
隠しユニット
隠しユニットとは上記のモデルの場合、入力と出力の間にある2つの中間層のことです。このユニットが多いほどネットワークは複雑な表現を学習できます。
損失関数とオプティマイザ
モデルには、損失関数と学習用の最適化が必要です。今回は2つに分類する問題であり、モデルは確率を出力するのでbinary_crossentropyという損失関数を使用します。
次のコードはオプティマイザと損失関数を使用するようにモデルを構成します。
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='binary_crossentropy',
metrics=['accuracy'])
検証セットを作成する
訓練データから10000件を検証データとして使用します。
x_val = train_data[:10000] partial_x_train = train_data[10000:] y_val = train_labels[:10000] partial_y_train = train_labels[10000:]
モデルを訓練する
batch_size=512, epochs=40に設定します。x_trainとy_trainにある全てのサンプルで40回反復させます。トレーニング中に検証セットから1万サンプルでモデルの損失と制度をモニタリングします。
history = model.fit(partial_x_train,
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
【結果】
Train on 15000 samples, validate on 10000 samples Epoch 1/40 15000/15000 [==============================] - 1s 67us/step - loss: 0.6917 - acc: 0.5495 - val_loss: 0.6897 - val_acc: 0.5820 Epoch 2/40 15000/15000 [==============================] - 1s 41us/step - loss: 0.6857 - acc: 0.6457 - val_loss: 0.6820 - val_acc: 0.7062 Epoch 3/40 <中略> Epoch 39/40 15000/15000 [==============================] - 1s 46us/step - loss: 0.0977 - acc: 0.9733 - val_loss: 0.3059 - val_acc: 0.8834 Epoch 40/40 15000/15000 [==============================] - 1s 53us/step - loss: 0.0939 - acc: 0.9756 - val_loss: 0.3088 - val_acc: 0.8832
モデルを評価する
テストデータを使ってモデルを評価します。以下のコードで損失と、正確さが分かります。損失値は値が低い方が良い結果です。
results = model.evaluate(test_data, test_labels) print(results)
【結果】
25000/25000 [==============================] - 1s 24us/step [0.329123981256485, 0.87228]
正確性は約87%でした。
訓練による正確性と損失のグラフを作成する
model.fit()は Historyオブジェクトを返します。このオブジェクトは訓練中におきたこと全てを含む辞書です。
history_dict = history.history history_dict.keys()
【結果】
dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
訓練中の正確性と損失、検証中の正確性と損失の計4つです。これらを使用して訓練時の損失と検証時の損失の比較、訓練時の正確性と検証時の正確性の比較ができます。
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" は 青い点
plt.plot(epochs, loss, 'bo', label='Training loss')
# b は青い線
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
【結果】
訓練中は訓練を重ねるごとに徐々に損失値が低下していますが、検証するときは25回目前後で最小値になりそれ以降は少し上昇しました。
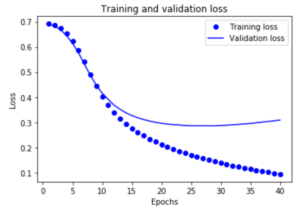
plt.clf() # グラフをクリアする
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
【結果】
訓練を重ねるごとに正確性は上昇していますが、検証結果による、25回目以降はほぼ横ばい(約0.87)でした。
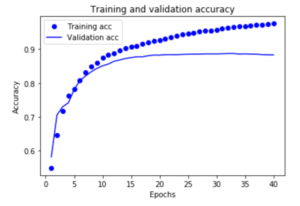
lossが減少し、Accuracyが増加することに注目してください。これは勾配効果最適化を使用するときに予想されます。反復ごとに必要な量を最小限に抑える必要があります。
約20エポック後にピークに達するため、この損失値と正確性(訓練するごとに正確性が100%に近く)は正しくはありません。これは過剰適合の例です。
この場合は、20回程度の反復の後に訓練を中止することで過剰適合を防ぐことができます。これはコールバックを使って自動的に行う方法があります。
まとめ
映画のレビューをポジティブかネガティブに分類するモデルの作成方法を学べました。
訓練をしながら検証を行うことで、モデルの損失値や正確性の推移を出すことができました。モデルの分析がしやすくなりますね。
反復回数が多かったためモデルが訓練用データに特化する過剰適合という状態になりました。
過剰適合を防ぐための方法は後のチュートリアルで出るそうです。








コメントを残す