
今回はTensorFlowのチュートリアルのオーバーフィットとアンダーフィット(Overfitting and underfitting)をやります。
はじめに
今までのチュートリアルで映画のレビューの分類や、車のデータから燃費を予測するモデルを学習させました。
訓練中に検証データを使って出力したモデルの精度の結果から、あるエポックの学習を界に精度がピークに達しそれ以降の学習では精度が下がっていきました。
これはモデルが訓練用データに過剰適合してしまったためです。本来、学習したモデルのあるべき姿はテストデータ(まだモデルが過去に学んだことのないデータ)に対して上手く一般化された結果を出力することです。
オーバーフィットの反対はアンダーフィットです。テストデータにまだ改善の余地がある場合はアンダーフィットが発生します。アンダーフィットが発生する原因はいくつかあります。
例えばモデルが貧弱、過剰に正規化されている、十分に訓練されていない場合です。これは、ネットワークが訓練データの関連パターンを学習していないために発生します。
オーバフィットやアンダーフィットが発生しないようにすることは重要です。適切なエポック数でモデルを訓練させることを理解することは非常に有用です。
過剰適合を防ぐためにはより多くの訓練データを使うことです。より多くのデータで訓練されたモデルほどより一般化されます。それが不可能になった場合の次の手段は、正則化のような手法を使うことです。
これらはモデルが保存できる情報の量と種類に制約を課します。少数のパターンしか記憶できないネットワークならば、最適化のプロセスはネットワークをより一般化させる最も顕著なパターンに集中するでしょう。
今回は、一般的な正則化の方法であるウェイト正則化と、ドロップアウトの2つを掘り下げます。これらを使ってIMDB映画レビューの分類を改善します。
動作環境
python3.6, tensorFlow 1.12.0, jupyter notebook
最初に利用するモジュールをインポートします。
import tensorflow as tf from tensorflow import keras import numpy as np import matplotlib.pyplot as plt
IMDBデータセットをダウンロード
文章をマルチホットエンコードにします。このモデルはすぐに過剰適合するでしょう。これは過剰適合がいつ発生するか、そしてどのように対処するかをデモするために使われます。
マルチホットエンコードとは0と1のベクトルのことです。
NUM_WORDS = 10000
(train_data, train_labels), (test_data, test_labels) = keras.datasets.imdb.load_data(num_words=NUM_WORDS)
def multi_hot_sequences(sequences, dimension):
# Create an all-zero matrix of shape (len(sequences), dimension)
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0 # set specific indices of results[i] to 1s
return results
train_data = multi_hot_sequences(train_data, dimension=NUM_WORDS)
test_data = multi_hot_sequences(test_data, dimension=NUM_WORDS)
plt.plot(train_data[0])
【結果】
マルチホットベクトルの1つが表示されます。単語のインデックスは頻度でソートされているため、インデックスが若いほど1が多く出現していることがわかります。
オーバーフィット
過剰適合を防ぐ最も簡単な方法はモデルのサイズ(パラメータ)を減らすことです。
モデルのパラメータが多いほど多く記憶でき、データに適合したモデルになります。
ディープラーニングモデルはトレーニングデータにフィットするのが得意ですが、本当の課題は一般化であり、フィットではありません。このことは肝に銘じて下さい。
一方ネットワークのパラメータが限られているほど一般化は容易ではありません。学習による損失を最小限に抑えるためには、より予測力のある圧縮表現を学ぶ必要があります。さらに、モデルを小さくしすぎると、トレーニングデータに合わせるのが難しくなります。
残念ながら、モデルの適切なサイズや構造を決定する方法はありません。様々な構造を使って実験する必要があるでしょう。
適切なモデルサイズを見つけるためには、比較的少数のパラメータやレイヤーから始めて、損失が減少するまでレイヤーのサイズを大きくしたり、新しいレイヤーを追加することがお勧めです。
ベースとして、Dense層のみを使ったシンプルなモデルを作ります。次に小さいバージョンと大きいバージョンを作って両方を比較します。
ベースラインモデル
[入力層]活性化関数:Relu関数
入力データ形式:(NUM_WORDS,)
[隠れ層]活性化関数:Relu関数
[出力層]活性化関数:Relu関数
オプティマイザー: adam
損失関数:binary_crossentropy
baseline_model = keras.Sequential([
# `input_shape` はここでのみ必要です。そうすることでsummary()が使えます。
keras.layers.Dense(16, activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dense(16, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
baseline_model.summary()
【結果】
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 16) 160016 _________________________________________________________________ dense_1 (Dense) (None, 16) 272 _________________________________________________________________ dense_2 (Dense) (None, 1) 17 ================================================================= Total params: 160,305 Trainable params: 160,305 Non-trainable params: 0 _________________________________________________________________
モデルに学習させます。
baseline_history = baseline_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
【結果】学習ごとに正確性や、損失値を出力しています。
Train on 25000 samples, validate on 25000 samples Epoch 1/20 - 9s - loss: 0.4937 - acc: 0.7932 - binary_crossentropy: 0.4937 - val_loss: 0.3409 - val_acc: 0.8766 - val_binary_crossentropy: 0.3409 Epoch 2/20 <中略> Epoch 19/20 - 6s - loss: 0.0040 - acc: 1.0000 - binary_crossentropy: 0.0040 - val_loss: 0.8218 - val_acc: 0.8532 - val_binary_crossentropy: 0.8218 Epoch 20/20 - 6s - loss: 0.0034 - acc: 1.0000 - binary_crossentropy: 0.0034 - val_loss: 0.8455 - val_acc: 0.8528 - val_binary_crossentropy: 0.8455
小さいモデルを作成する
今作成したベースラインモデルと比較するために、隠れユニットの少ないモデルを作成します。
smaller_model = keras.Sequential([
keras.layers.Dense(4, activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dense(4, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
smaller_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
smaller_model.summary()
【結果】
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_3 (Dense) (None, 4) 40004 _________________________________________________________________ dense_4 (Dense) (None, 4) 20 _________________________________________________________________ dense_5 (Dense) (None, 1) 5 ================================================================= Total params: 40,029 Trainable params: 40,029 Non-trainable params: 0 _________________________________________________________________
上記と同様にsmaller_modelを学習させます。
smaller_history = smaller_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
【結果】
smaller_history = smaller_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
より大きなモデルを作成する
より大きなモデルを作成して、いかに早く過剰適合し始めるかを見ることができます。
bigger_modelを作成します。
bigger_model = keras.models.Sequential([
keras.layers.Dense(512, activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dense(512, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
bigger_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
bigger_model.summary()
【結果】
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_6 (Dense) (None, 512) 5120512 _________________________________________________________________ dense_7 (Dense) (None, 512) 262656 _________________________________________________________________ dense_8 (Dense) (None, 1) 513 ================================================================= Total params: 5,383,681 Trainable params: 5,383,681 Non-trainable params: 0 _________________________________________________________________
bigger_modelを学習させます。
bigger_history = bigger_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
【結果】
Train on 25000 samples, validate on 25000 samples Epoch 1/20 - 24s - loss: 0.3506 - acc: 0.8517 - binary_crossentropy: 0.3506 - val_loss: 0.2980 - val_acc: 0.8788 - val_binary_crossentropy: 0.2980 Epoch 2/20 - 22s - loss: 0.1386 - acc: 0.9495 - binary_crossentropy: 0.1386 - val_loss: 0.3630 - val_acc: 0.8623 - val_binary_crossentropy: 0.3630 <中略> Epoch 19/20 - 23s - loss: 1.7445e-05 - acc: 1.0000 - binary_crossentropy: 1.7445e-05 - val_loss: 0.8495 - val_acc: 0.8731 - val_binary_crossentropy: 0.8495 Epoch 20/20 - 25s - loss: 1.5732e-05 - acc: 1.0000 - binary_crossentropy: 1.5732e-05 - val_loss: 0.8552 - val_acc: 0.8730 - val_binary_crossentropy: 0.8552
トレーニングと検証の損失をプロットする
作成した3つのモデルの学習推移をグラフに起こします。実線はトレーニングデータによる損失を示し、破線は検証データによる損失を示します(検証データによる損失が小さいほど良いモデルです)
def plot_history(histories, key='binary_crossentropy'):
plt.figure(figsize=(16,10))
for name, history in histories:
val = plt.plot(history.epoch, history.history['val_'+key],
'--', label=name.title()+' Val')
plt.plot(history.epoch, history.history[key], color=val[0].get_color(),
label=name.title()+' Train')
https://allneko.club/wp-admin/post-new.php#
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0,max(history.epoch)])
plot_history([('baseline', baseline_history),
('smaller', smaller_history),
('bigger', bigger_history)])
【結果】
smallerはbaselineよりも遅く過剰適合を開始し、パフォーマンスがよりゆっくり低下していくことがわかります。
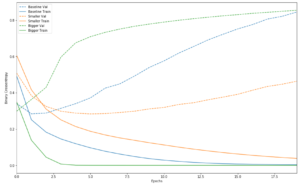
biggerは1回目のエポックの後から、過剰適合を始め急速に過剰適合していくことに注目してください。ネットワークのキャパシティーが大きいほど訓練データのモデル化が早くなりますが、過剰適合の影響を受けやすくなります。








コメントを残す